This post is part of the Epilepsy Blog Relay™ which will run from March 1 through March 31, 2018. Follow along and add comments to posts that inspire you!
As the parent of a child with epilepsy, I rarely sleep through the night. Instead, I periodically wake to check in on my son. We use a wireless camera that has an app that we run on an iPad that I prop up beside our bed. I can see in to his room, even at night, and hear any activity or seizures. For the most part, it’s a good setup. But occasionally a wireless issue will cause the connection to drop. I’ll wake up facing a dark screen, wondering if I missed a seizure as I fumble in the dark to restart the app.
That scenario repeats a few times a month, which is why the news that the FDA approved the Empatica Embrace as a medical device was so exciting. The Embrace is a wearable device that detects generalized tonic-clonic seizures and sends an alert to caregivers. Devices like the Embrace will provide a piece of mind to many people with seizures and those that care for them.
Unfortunately for us, we haven’t yet found a device that can reliably detect my son’s seizures. His seizures are short and without much movement, making them harder to detect. Generally, the longer a seizure is and the more activity it generates, the more likely it will be detected. But with new sensors and smarter algorithms, these devices will continue to improve. They’ll have a higher sensitivity to detect shorter and more subtle seizures. Instead of relying on my own eyes and ears to catch every seizure, I’m hopeful that these devices will work for my son someday, too.
Since the theme this week is technology and epilepsy, I thought I would spend some time talking about the magic behind these devices.
Detection versus Prediction
Detection
First, I wanted to differentiate between detection and prediction. Devices like the Embrace focus on seizure detection. Detection figures out when a seizure is happening. The device monitors activity from embedded sensors and runs it through an algorithm. The algorithm has been trained to look for patterns that look like seizure activity. Once it is confident enough that a seizure is occurring, it will send out an alert.
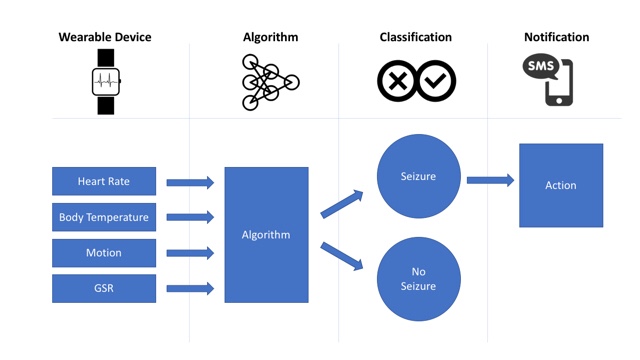
Prediction
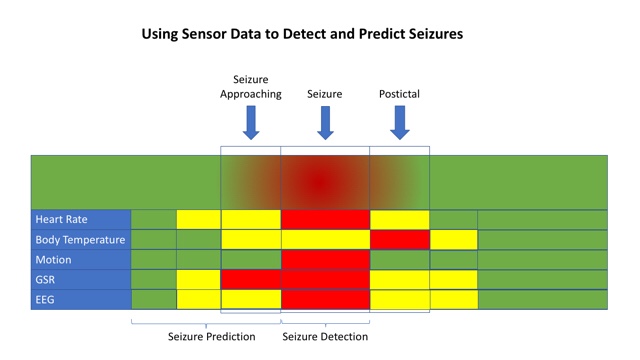
Seizure prediction tries to figure out when a seizure is likely to happen. Some people have auras or other cues that let them know that a seizure is coming. Imagine a device that could provide that same warning to everyone. This is a hard but achievable goal. The clues may be more subtle and harder to see. We may need more data or new sensors, but we’re well on our way to developing them. When we figure it out, the warning it provides cold allow a person about to have a seizure to go sit down or get to a safe area. It could alert caregivers ahead of time so that they provide help before or during the seizure.
Training an Algorithm
Both seizure detection and seizure prediction use much of the same data but for different goals. The techniques used to learn the algorithm are similar, too. Data is collected from a group of people wearing different sensors. The data includes both seizure and non-seizure activity and it’s fed in to a computer with a label such as “seizure” or ”no seizure.” The computer learns the difference between the two and creates a model that can be used to look at new data to classify it as a “seizure” or ”not a seizure.” The more examples the algorithm sees, the better it gets at identifying the common traits in the data that are associated with a seizure.
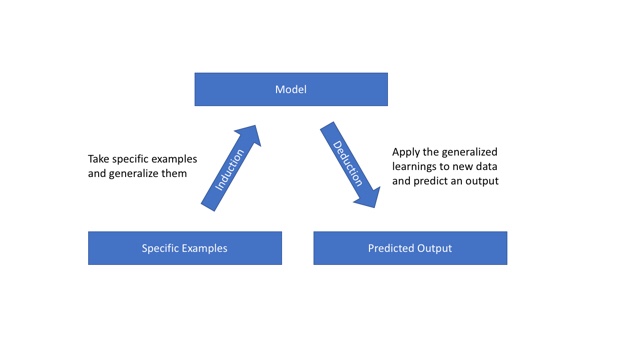
The process is similar to teaching an algorithm to identify a cat. You feed the system a bunch of examples of cats and it identifies that a cat has two eyes, to ears, a nose, and whiskers. It generalizes traits using a technique called induction. Once it generalizes the traits, it can use them to identify a cat that it has never seen before using those traits. This is called deduction.
The same approach happens with seizures. People and seizures are different. If we trained a model to look for a specific heart rate, it wouldn’t be useful because that would differ for everyone. Instead, we train a model to associate common changes that happen during a seizure. Then, when it sees the data coming in from sensors in a device, it looks for those similar markers to decide how to classify the data.
No Algorithm Is Perfect
As in the cat example, there are an infinite number of combinations of data points necessary to always get it right. We can’t practically train a model by showing it every angle of every cat that might exist. And we can’t give it data reflecting every possible seizure for every person. But we don’t have to. The magic of these algorithms is that they can do a pretty good job using subsets of the data. But that does mean they can make mistakes.
There are two types of mistakes that are the most common: false positive and false negative. In the case of seizure detection, a false positive is when the algorithm said there was a seizure but there wasn’t. A false negative would be when the algorithm didn’t think there was a seizure but there was.
These two error types present different challenges. In seizure detection, a false positive means that a caregiver might have been alerted. This can be annoying, especially if it happens too much, like The Boy Who Cried Wolf. Too many false positives means people may turn off the notification feature or stop wearing the device altogether.
In seizure detection, the false negative is a much more severe problem because it means a seizure occured but the algorithm missed it. That means no notification was sent to alert a caregiver. If that is the primary purpose for the device then it can’t be relied on and won’t be used.
Making Things Better
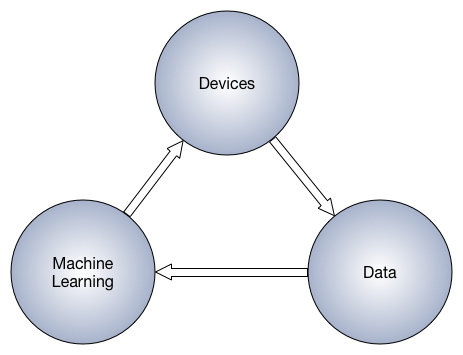
The good news is that algorithms can learn from their mistakes and get better. We can use the times it was right and wrong to retrain the algorithm so that it can get better. That’s what Google, Facebook, and every other company that uses data does to make their products better. A popular concept in the world of machine learning and AI products is the Virtuous Circle of AI.
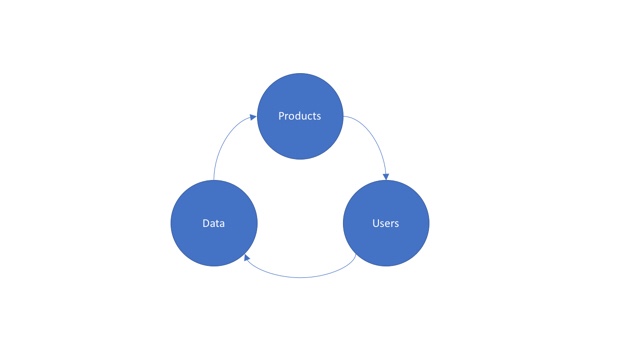
We create products and give them to customers. The customers use the product and generate more data. The data is used to make the product better by making the algorithms better or adding new features. This is how Alexa gets better at understanding what you’re asking for, how Google gives you better search results, and how music and movie recommendations today are many times more accurate than even a few years ago. In the same way, as more devices like the Embrace find their way on to the market and more people use them, these products will use the data to get better, too.
NEXT UP: Be sure to check out the next post tomorrow by Joe Stevenson at epilepticman.com for more on epilepsy awareness. For the full schedule of bloggers visit livingwellwithepilepsy.com.
Don’t miss your chance to connect with bloggers on the #LivingWellChat on March 31 at 7PM ET.